Table Partitioning In MySQL NDB Cluster And What’s New (Part IV)
Whats new in NDB Cluster 8.0 version (8.0.23)
With new configuration variables introduced in NDB cluster version 8.0.23, user now have more control in table partitioning. Below are the new config variables that can influence the table partitioning scheme:
PartitionsPerNode:
In earlier cluster versions, the default number of table partitions is based on the number of LDM threads running on a node multiplied by the number of data nodes in the cluster. User can not set any random values to MaxNoOfExecThreads (#LDM) rather the value should be less than or equal to NoOfFragmentLogParts. With cluster version 8.0.23, user can have many no of LDM threads assign to a data node.
The rationale is:
- Having many LDMs allows a data node to make good use of modern hardware.
- Having one partition per LDM per node gives good balance.
- However having many partitions can affect range scan scalability and performance, so the number of partitions per table should be constrained.
- In cluster 8.0.23 version, the advantage of query threads allows further read throughput scaling on a single table partition.
- This can mean that we need not always add partition to scale up read throughput.
- From cluster 8.0.23 version, it is possible to set the default number of partitions separately to the number of LDMs, using the new PartitionsPerNode parameter.
The PartitionsPerNode config variable allows the number of partitions to be decoupled from the number of LDMs, so that even with many LDM threads, we don’t automatically have many partitions in every table.
To use this config variable, user should set ClassicFragmentation=0. When ClassicFragmentation=0, the number of LDM threads is no longer part of calculating the partition count.
ClassicFragmentation:
This config variable controls whether to use the number of LDMs for table partitons or not. By setting it to 1 or true, the number of LDMs will be used to decide the number of table partitons which is the default behaviour. When it set to 0 or false then PartitionsPerNode will decide the number of partitions.
For an example, with a 4 data nodes cluster with PartitionsPerNode=4, and ClassicFragmentation=0 then total number of partitions would be (no of nodes * PartitionsPerNode) i.e. 4 * 4 = 16.
Case -I:
Let’s start a NDB cluster with 8.0.23 version or later. I have set the new config variables ClassicFragmentation=0 and PartitionsPerNode=4 in the config.ini file like below:

Let’s start the cluster:

Now create a table ‘t1’ and inserts few rows into it.

Let’s check the partition count from ndb_desc API program:

So from the above image we can see the total number of partition is 16. As we saw above, the calculation goes like: Number of nodes * PartitionsPerNode i.e. 4 * 4 = 16.
Case -II:
Let’s set ClassicFragmentation=1, PartitionsPerNode=4 and MaxNoOfExecutionThreads=12 (#ldm: 6). As you see above, by setting ClassicFragmentation to 1 means the partition count will be based on the LDMs than the PartitionsPerNode. Let’s check it.

Let’s start the cluster. Create a database ‘test1’, table ‘t1’ and insert few rows into it. Then run ndb_desc to check the partition count:
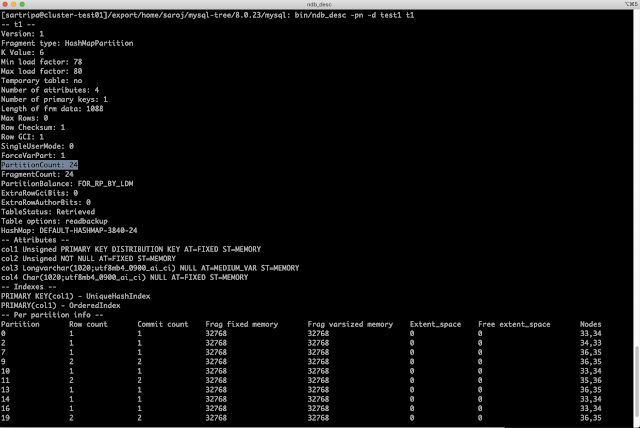
From the above image, we can see the partition count is showing as 24. Since we set ClassicFragmentation=1 so partition count will be based on LDMs. In the above case, we have MaxNoOfExecutionThreads=12 i.e. number of LDMs =6 and number of nodes=4. So total number of partitions would be (number of LDMs * number of nodes) i.e. 6 * 4 = 24.
Case -III:
Let’s set ClassicFragmentation=0, PartitionsPerNode=4 and MaxNoOfExecutionThreads=12 (#ldm: 6). This time let’s create the table with user partitioning i.e. by PARTITIONS 8.
Let’s start the cluster. Create a database ‘test1’, table ‘t1’ and insert few rows into it. Then run ndb_desc to check the partition count:

Let’s check the partition count from ndb_desc:

From the above image, we can see that PartitionCount:8 as we explicitly state to create ‘8’ partitions while creating the table so here PartitionPerNode is ignored even though it is set in the config file.
To know more details on these new config variables, please refer to the cluster reference manual here.
This concludes our discussion of NDB Cluster table partitioning.
With new configuration variables introduced in NDB cluster version 8.0.23, user now have more control in table partitioning. Below are the new config variables that can influence the table partitioning scheme:
- PartitionsPerNode
- ClassicFragmentation
PartitionsPerNode:
In earlier cluster versions, the default number of table partitions is based on the number of LDM threads running on a node multiplied by the number of data nodes in the cluster. User can not set any random values to MaxNoOfExecThreads (#LDM) rather the value should be less than or equal to NoOfFragmentLogParts. With cluster version 8.0.23, user can have many no of LDM threads assign to a data node.
The rationale is:
- Having many LDMs allows a data node to make good use of modern hardware.
- Having one partition per LDM per node gives good balance.
- However having many partitions can affect range scan scalability and performance, so the number of partitions per table should be constrained.
- In cluster 8.0.23 version, the advantage of query threads allows further read throughput scaling on a single table partition.
- This can mean that we need not always add partition to scale up read throughput.
- From cluster 8.0.23 version, it is possible to set the default number of partitions separately to the number of LDMs, using the new PartitionsPerNode parameter.
The PartitionsPerNode config variable allows the number of partitions to be decoupled from the number of LDMs, so that even with many LDM threads, we don’t automatically have many partitions in every table.
To use this config variable, user should set ClassicFragmentation=0. When ClassicFragmentation=0, the number of LDM threads is no longer part of calculating the partition count.
ClassicFragmentation:
This config variable controls whether to use the number of LDMs for table partitons or not. By setting it to 1 or true, the number of LDMs will be used to decide the number of table partitons which is the default behaviour. When it set to 0 or false then PartitionsPerNode will decide the number of partitions.
For an example, with a 4 data nodes cluster with PartitionsPerNode=4, and ClassicFragmentation=0 then total number of partitions would be (no of nodes * PartitionsPerNode) i.e. 4 * 4 = 16.
Case -I:
Let’s start a NDB cluster with 8.0.23 version or later. I have set the new config variables ClassicFragmentation=0 and PartitionsPerNode=4 in the config.ini file like below:
Let’s start the cluster:
Now create a table ‘t1’ and inserts few rows into it.
Let’s check the partition count from ndb_desc API program:
So from the above image we can see the total number of partition is 16. As we saw above, the calculation goes like: Number of nodes * PartitionsPerNode i.e. 4 * 4 = 16.
Case -II:
Let’s set ClassicFragmentation=1, PartitionsPerNode=4 and MaxNoOfExecutionThreads=12 (#ldm: 6). As you see above, by setting ClassicFragmentation to 1 means the partition count will be based on the LDMs than the PartitionsPerNode. Let’s check it.
Let’s start the cluster. Create a database ‘test1’, table ‘t1’ and insert few rows into it. Then run ndb_desc to check the partition count:
From the above image, we can see the partition count is showing as 24. Since we set ClassicFragmentation=1 so partition count will be based on LDMs. In the above case, we have MaxNoOfExecutionThreads=12 i.e. number of LDMs =6 and number of nodes=4. So total number of partitions would be (number of LDMs * number of nodes) i.e. 6 * 4 = 24.
Case -III:
Let’s set ClassicFragmentation=0, PartitionsPerNode=4 and MaxNoOfExecutionThreads=12 (#ldm: 6). This time let’s create the table with user partitioning i.e. by PARTITIONS 8.
Let’s start the cluster. Create a database ‘test1’, table ‘t1’ and insert few rows into it. Then run ndb_desc to check the partition count:
Let’s check the partition count from ndb_desc:
From the above image, we can see that PartitionCount:8 as we explicitly state to create ‘8’ partitions while creating the table so here PartitionPerNode is ignored even though it is set in the config file.
To know more details on these new config variables, please refer to the cluster reference manual here.
This concludes our discussion of NDB Cluster table partitioning.



Comments
Post a Comment